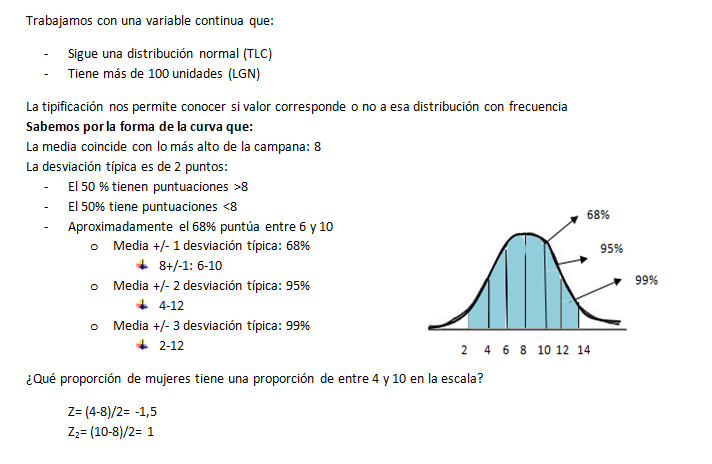
SEMINARIO 3
En esta entrada dejaré ejemplos prácticos de lo publicado hasta ahora de la parte estadística. Este seminario nos sirvió para afianzar nuestros conocimientos sobre la materia y fue un apoyo a lo que ya habíamos visto en clase, por ello pienso que para no volver a explicar la misma información, una buena forma de valorar lo aprendido es con ejemplos.
En este seminario, también vimos como usar el programa Epi Info, necesario para realizar el estudio de nuestro proyecto de investigación. Muy pronto os contaré en que se basa nuestro proyecto de investigación y en la siguiente entrada os dejaré unos vídeos sobre como usar Epi Info
Ejemplo 1. Realizar una tabla de frecuencia.

Xn (peso más alto) = 6.1 kg / X1 (peso más bajo) = 3.3 kg
La manera de realizar este ejemplo es:
Primero
calculamos el recorrido (Diferencia entre el valor más alto y el valor más
bajo).
Re = xn
–x1= 6.1 – 3.3 = 2.8
Para calcular el intervalo: si no se nos dice nada sobre en número de intervalos, se obtiene calculando la raíz cuadrada del número de datos observados.
La raíz cuadrada de 40 = 6.32. Por lo tanto tomaremos 6 intervalos, es decir, 6 serán el número de filas que tendrá nuestra tabla.
Por último, el recorrido es 2.8 y si lo dividimos por el número de intervalos tendremos la amplitud de cada uno de ellos.
2.8 / 6 = 0.46 (Amplitud)
-

Una vez con nuestra tabla realizada, podemos representar los datos obtenidos en los diferentes tipos de gráficas (Explicación de cómo hacerlo en el vídeo de la entrada referida al tema 7)
Ejemplo 2. Unas enfermeras han registrado las edades de nueve niños vacunados durante una sesión, obteniendo los siguientes datos:
3, 2, 4, 2, 1, 3, 5, 3, y 4 meses
Calcular:

Ejemplo 3. En un centro de salud se pretende realizar un estudio sobre las cifras de
tensión arterial diastólica en un grupo de 30 pacientes que acuden a consulta
de enfermería en los programa de atención al paciente diabético. Los enfermeros
del programa midieron la TAD de estos 30 pacientes, obteniendo las siguientes
cifras (datos en mm de Hg)



Ejemplo 4. En un
estudio sobre cuidadores principales en familias con personas dependientes, se
miden las edades de los cuidadores principales, obteniéndose la siguiente gráfica: