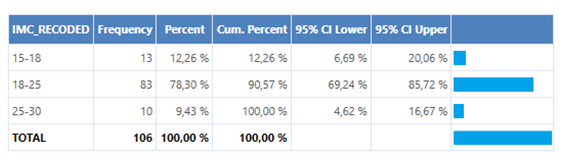
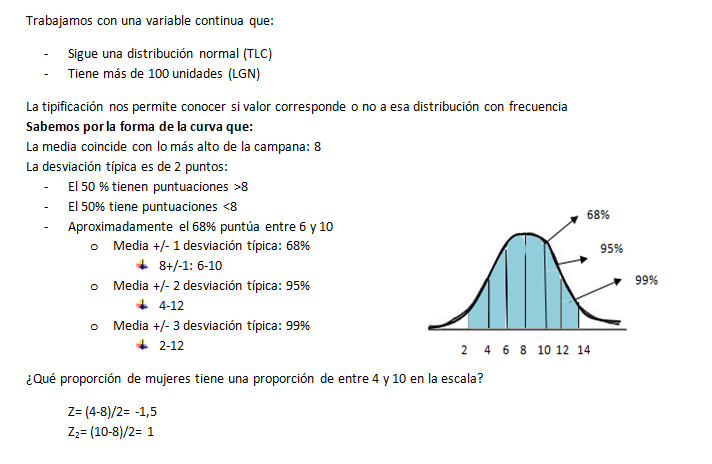
Por ahora, esta será la última entrada del blog. Espero que mis conocimientos sobre estadística os puedan servir de ayuda para, en un futuro, realizar cualquier tipo de trabajo de investigación.
He querido que este blog fuese algo dinámico y divertido, que además de la teoría contuviese material audiovisual y algunas otras entradas que no pertenecieran estrictamente al campo de la estadística, pero sí de la enfermería. ¡Espero haberlo conseguido y que os halla gustado!
En cuanto a lo aprendido, la verdad es que la creación de nuestro propio blog ha sido una herramienta muy útil, al menos para mí lo ha sido. Con esto, hemos podido aprender a movernos un poco más por el mundo virtual. Puede ser que en un futuro necesitemos una plataforma para compartir nuestros trabajos o experiencias y que mejor forma de hacerlo que retomando nuestro blog.
Al principio pensé que el blog sería una tarea algo pesada, por el hecho de tener que escribir cada tema que veíamos en clase. Pero la verdad es que hacer esto me ha servido para repasar los conocimientos que estudiaba, el blog me resulta muy útil para repasar ya que de manera resumida contiene todos los aspectos que hemos visto en clase y seminarios.
Otro aspecto muy importante es que nos ha permitido realizar búsquedas bibliográficas, tanto en Internet como en bases de datos. Por lo tanto, hemos aprendido a realizar este tipo de búsquedas, que como dije en mi presentación, nos resultará muy útil a la hora de realizar nuestro Trabajo Final de Grado (TFG) u otros trabajos que llevemos a cabo en cualquier asignatura de nuestra carrera.
La investigación en enfermería es aún desconocida para muchos y otros no encuentran los medios necesarios para realizarla por ello, estoy muy satisfecha con lo aprendido en clase y seminarios, además de los conocimientos impartidos por los profesores de la asignatura ya que nos han acercado un poco más al mundo de la investigación y con ello hemos aprendido las nociones necesarias para realizar nuestros proyectos.
Las sesiones en pequeño grupo o seminarios han sido muy buenas ya que hemos expuesto nuestros trabajos, así también vamos practicando para nuestro TFG, y nos ha resultado de gran ayuda ya que hemos podido ampliar los conocimientos, reforzarlos y aclarar las dudas que tuviésemos acerca del temario de la asignatura.
Creo que esto es todo por ahora, así que ¡hasta pronto!
Me gustaría despedirme con los 5 Nunca de Steve Jobs:
- Nunca darse por vencido.
- Nunca aparentar.
- Nunca mantenerse inmóvil.
- Nunca aferrarse al pasado.
- Nunca dejar de soñar.